讓硅谷震驚的中國大模型!
國際電子商情27日訊 過去一周,來自中國的DeepSeek R1模型“攪動”整個海外AI圈。
什么是DeepSeek?它為何在全球范圍內引起轟動?與DeepSeek相關的公司有哪些?
公開資料顯示,中國AI初創公司深度求索(DeepSeek)成立于2023年5月,是一家大模型創業公司。僅成立半年后,DeepSeek就推出了免費商用、完全開源的代碼大模型DeepSeek Coder。2024年5月,該公司發布開源模型DeepSeek V2,將推理成本降低近百倍,一躍成名。
2024年12月27日,DeepSeek推出了開源模型DeepSeek-V3。
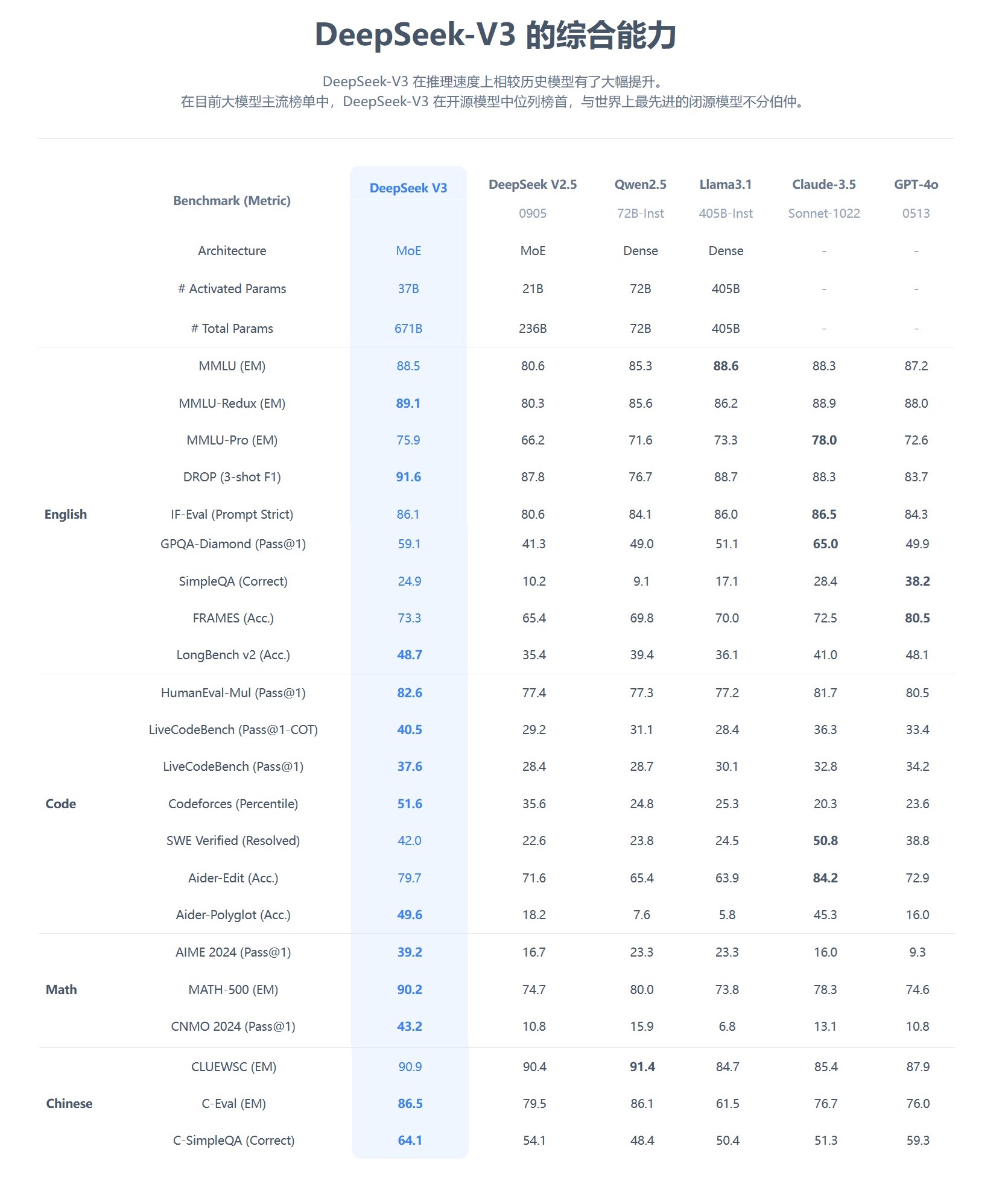
這款模型在多項基準測試表現優異,超越業內主流頂尖模型,特別是在知識問答、長文本處理、代碼生成和數學能力等方面。例如,在MMLU、GPQA等知識類任務中,DeepSeek-V3的表現接近國際頂尖模型Claude-3.5-Sonnet。
在數學能力方面,更是在AIME 2024和CNMO 2024等測試中創造了新的記錄,超越所有已知的開源和閉源模型。同時,其生成速度較上代提升了200%,達到60TPS,大幅改善了用戶體驗。
當時,在國外大模型排名Arena上,DeepSeek-V3在所有模型中排名第七,在開源模型排第一。而且,DeepSeek-V3是全球前十中性價比最高的模型。
意料之外的是,在DeepSeek-V3發布不到1個月之后,更“炸街”的DeepSeek-R1來了!
2025年1月20日,DeepSeek正式開源R1推理模型。性能對齊OpenAI-o1,正式版DeepSeek-R1在后訓練階段大規模使用了強化學習技術,在僅有極少標注數據的情況下,極大提升了模型推理能力。在數學、代碼、自然語言推理等任務上,性能比肩OpenAI o1正式版。
目前普遍認為,DeepSeek的R1發布標志著推理模型研究的重要轉折點,而在此之前推理模型一直是工業研究的重要領域,但缺乏一篇開創性的論文,就像AlphaGo使用強化學習下了無數盤圍棋并優化其策略以獲勝一樣,DeepSeek正在使用相同的方法來提升其能力,因此2025年可能會成為強化學習的元年。
1月24日,在國外大模型排名Arena上,DeepSeek-R1基準測試已經升至全類別大模型第三,其中在風格控制類模型(StyleCtrl)分類中與OpenAI o1并列第一。而其競技場得分達到1357分,略超OpenAI o1的1352分。
為何DeepSeek火爆出圈?一方面,它以較低的訓練成本實現了媲美OpenAI o1性能的效果,詮釋了中國在工程能力和規模創新上的優勢;另一方面,它也秉持開源精神,熱衷分享技術細節。
值得注意的是,據DeepSeek發布的技術報告顯示,DeepSeek-R1的訓練費用僅為OpenAI最新大模型的三十分之一。
DeepSeek-V3在僅使用2048塊H800 GPU的情況下,完成了6710億參數模型的訓練,成本僅為557.6萬美元,遠低于其他頂級模型的訓練成本。
作為參照,斯坦福大學和Epoch AI的研究人員去年年中發表了一項研究表明,到2027年,最大型的模型的訓練成本將超過10億美元。另外,第三方研究公司Gartner研究預測顯示,到2028年Google、Microsoft和AWS等超大規模企業僅在AI服務器上的支出就將高達5000億美元。
因此,不少業者認為,DeepSeek的低成本意味著,大模型對算力投入的需求可能會從訓練側向推理側傾斜,即未來對推理算力的需求將成為主要驅動力。而英偉達等硬件商的傳統優勢更多集中在訓練側,這可能會對其市場地位和戰略布局產生影響。
DeepSeek的另一個顯著優勢是“開源”。
在開源策略上,R1采用MIT License,給予用戶最大程度的使用自由,支持模型蒸餾,可將推理能力蒸餾到更小的模型,如32B和70B模型在多項能力上實現了對標o1-mini的效果,開源力度甚至超越了此前一直被詬病的Meta。
Meta首席AI科學家Yann Lecun評價稱,DeepSeek-R1面世與其說意味著中國公司在AI領域正在超越美國公司,不如說意味著開源大模型正在超越閉源。
1月22日,美國媒體Business Insider報道稱,DeepSeek-R1模型秉承開放精神,完全開源,為美國AI玩家帶來了麻煩。開源的先進AI可能挑戰那些試圖通過出售技術賺取巨額利潤的公司。
據不完全統計,目前DeepSeek的關聯公司涵蓋四類:股權關聯方、算力基礎設施供應商、垂直領域合作方、業務協同方。
(1)股權關聯方
每日互動:幻方量化(Deepseek母公司)二股東,為DeepSeek提供海量用戶行為語料數據等。
浙江東方:通過旗下杭州東方嘉富基金參投Deepseek天使輪。
華金資本:珠海國資旗下投資平臺間接參與DeepSeekPre-A輪融資。
(2)算力基礎設施供應商
中科曙光:承建DeepSeek杭州訓練中心液冷系統。
浪潮信息:為Deepseek北京亦莊智算中心提供AI服務器集群及英偉達H800+自研AIStation管理平臺。
潤澤科技:廊坊數據中心為Deepseek提供3000+機柜資源。
航錦科技:旗下超擎數智為Deepseek提供光模塊和交換機。
(3)垂直領域合作方
科大訊飛:在教育領域接入了DeepSeek-Math模型,并聯合推出了AI數學輔導應用“星火助學”。
拓爾思:與Deepseek聯合開發金融奧情大模型,已在中信證券等機構部署智能研報生成系統。
金山辦公:WPS智能寫作接入DeepSeek-Writer API,公文生成效率提升3倍,錯誤率下降90%。
卓創資訊:與幻方量化在金融語料庫方面存在合作,其數據資源或用于Deepseek模型的訓練和優化。
(4)業務協同方
并行科技:為DeepSeek提供多種計算技術手段,顯著提升其計算能力。
競業達:與DeepSeek大模型對接中。
可見,隨著DeepSeek、Minimax等中國公司在AI領域的崛起,全球AI竟爭格局正在發生微妙變化。如果中國公司能夠以更低的成本實現同等或更好的性能開源大模型,海外開源和閉源模型或都受到挑戰。此外應用端在字節豆包帶動下持續對商業化場景展開探索,中國AI公司和開源模型或將持續推動大模型產業和相關AI應用的升級。
信息來源:ESM China
日期:2025年2月6日









